Before
In this project, we will talk about out toy project to categorise the quality of playing roughly. We use Sampled CNN for this project.
This is not post of technology.
I’ll show you followings on the article.
- What we are doing
- What we are going to do
- What we will do
Dataset
Yugang Hong, Our CMO(Chef Marketing Officer) make small dataset for this toy project.
Not Chef Music Officer
There are 15 music samples. 5 music samples for each A, B and C class. The length of music is between 1m30s ~ 2m30s.
Pre-processing
Basically music is very high dimentional data. So we need to pre-process before using deep-learning. In this project we resize sample rate to 500(25200 in general). And splited to 10s duration.
If you input a music, this model will split your music as 10s and merge the results from each segment.
Development Environment
We use DeepLearningVM from Google Cloud Service.
We use ‘NVIDIA K80’ which specification in detail is as followings:
- 4992 NVIDIA CUDA cores with a dual-GPU design
- Up to 2.91 teraflops double-precision performance with NVIDIA GPU Boost
- Up to 8.73 teraflops single-precision performance with NVIDIA GPU Boost
- 24 GB of GDDR5 memory
- 480 GB/s aggregate memory bandwidth
- ECC protection for increased reliability
- Server-optimised to deliver the best throughput in the data center
Model
We use Sampled CNN from KAIST on 2017. In this model we approach to music with sample-level not frame-level. By sample 2~3 frames, we can get more locality without too much increasing on computation.
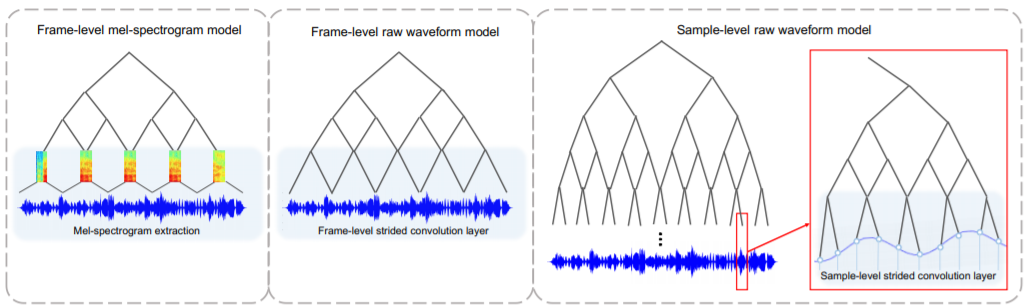
In each layer we can get more specific representation for the music. This make we can recognize each sample from another.
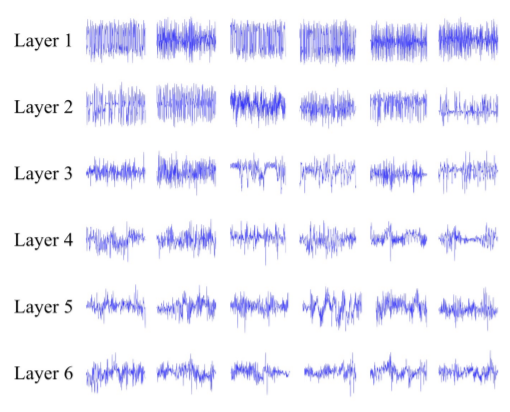
Result & Discussion
In following diagram, we can check each sample of music is clustered with axis ‘A-part’. Because we split entier music to 10s segment, there are 15~25 segments for each music sample.
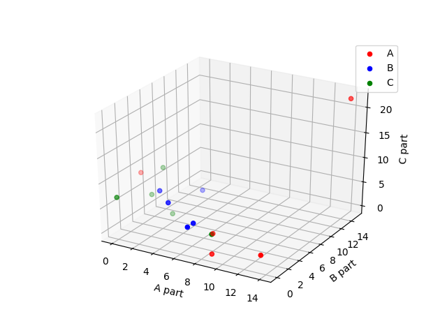
There are two main discussion.
- We can check quality of music with well-labeld music
- Of course, we don’t know what is A class music exatly… but at least we can cluster music!
- We can’t utilize ‘B part’ and ‘C part’ currently.
- When we check the ‘B part’ and ‘C part’ almost of them are silent part
- But in entire music silent part is also important for A class playing(e.g. dynamic scale)
- We need to find a way to get more global context from music
For future work
In this project, we check we can clutster image with deep learning. This means we can found proper representation of music!
Although we need to focus on how to get global context of music. But this need more powerful computing and better models. So there will be 2nd toy project for that!